
Országreklám: 18 milliárdos keretszerződést írt alá Balásy cégeivel a Visit Hungary Zrt.
A New Land Media Kft. és a Media Dynamics Kft. feladata lesz a turisztikai kereslet ösztönzése belföldön és külföldön egyaránt.

Magyarországon, de a régió más országaiban is előszeretettel szolgáltatnak közérdekű adatokat .pdf formátumban a kormányzati szervek. A .pdf formátumnak a számos előnye mellett egy – az adatokkal való munka szempontjából óriási – hátránya van: az adatokat nem lehet szerkeszteni.
A közérdekű adatigénylésekre, például a KiMitTud oldalon, a válaszok nagy része .pdf-ben érkezik, ezt a formátumot használja letölthető dokumentumai számára gyakorlatilag mindenki. Egy-egy ilyen dokumentumból nehéz, sokszor szinte lehetetlen az adatokat olyan adatcsere (machine-readable) formátumra hozni, amit már könnyen lehet szerkeszteni, megtisztítani és különféle szempontok szerint rendezni.

A jó hír az, hogy számos módszer és alkalmazás létezik az adatok .pdf dokumentumból való kinyerésére – jelen poszt ezek közül röviden bemutat néhányat, lazán követve a School of Data leírásait. A rossz hír viszont, hogy nem létezik egyetlen, minden .pdf dokumentum esetén könnyen alkalmazható, hatékony módszer.
Aki ilyesmire adja a fejét, az készüljön fel arra, hogy kísérleteznie és fórumoznia kell, sok türelem és némi minimális programozási tudás sem árt.
Könnyebb eleve használható adatokat kérni
A .pdf-problémát a legkönnyebben úgy meg lehet kerülni, hogy adatigénylés benyújtásakor megkérjük az adatgazdát, hogy az adatokat a .pdf dokumentum mellett adatcsere formátumban (.xls, JSON, CSV, XML) is mellékelje. Ezt az adatgazda elvben könnyen teljesítheti, hiszen ők is valamilyen szerkeszthető formátumból exportálják .pdf-be az adatokat.
Ideális esetben, ha teljesítik a kérésünket, akkor lesz egy, szépen formázott, nyomtatóbarát .pdf formátumú dokumentumunk, és egy másik dokumentumunk, mellyel dolgozni lehet.
A vízválasztó: kép vagy szöveg alapú?
A .pdf dokumentumok alapvetően kétfélék: kép vagy szöveges alapúak. Előbbiek rendszerint a kinyomtatott, majd beszkennelt és képként .pdf-be exportált dokumentumok – ezeket úgy lehet felismerni, hogy sem a keresés (Ctrl+F) funkció, sem pedig a kijelölés (Ctrl+C) nem működik.
A szöveges alapú dokumentumokban működik a keresés és kijelölés funkció, éppen ezért a másolás, adatcsere formátumra hozás is könnyebb.
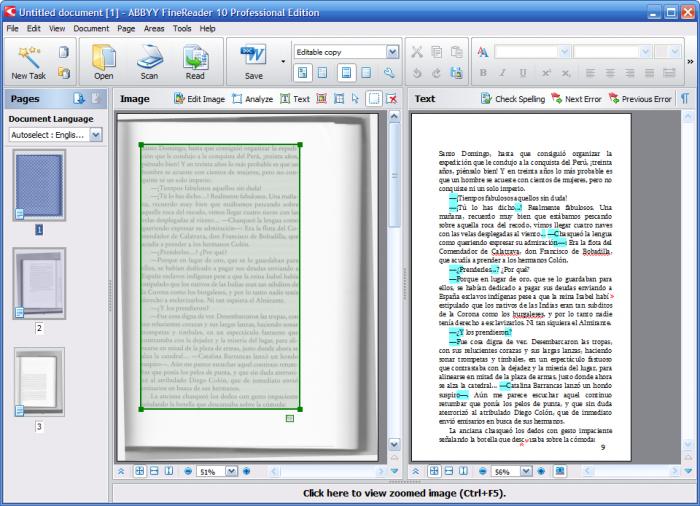
Ha kép alapú a dokumentum, az OCR megoldás
Valamilyen, Optical Character Recognition (OCR) szoftver a megoldás a kép alapú dokumentumok számára. Jelenleg az ABBYY Finereader a legelterjedtebb program, előnye, hogy a magyar nyelvet is felismeri. Hátránya, hogy csak korlátozott alkalommal futtatható ingyenesen – a korlátozás nélküli használathoz meg kell vásárolni. Több ingyenes alkalmazás is létezik – ezek nagyrészt a Google tulajdonában levő Tesseract-ra épülnek.
Ha a szkennelt dokumentum rossz minőségű, gyűrött, vagy foltos, esetleg a szöveg és a fehér felület közötti kontrasztot kell kiemelni, akkor az unpaper vagy a Scan Tailor lehet megoldás.
Fontos tudni, hogy kép alapú dokumentumok esetén a munkát sosem lehet teljesen automatizálni – ha nagy számú dokumentumot készül feldolgozni, akkor jó ötlet önkénteseket bevonni.
Szöveg alapú dokumentum: nyert ügy?
A szöveg alapú dokumentumokból adatokat kinyerni valamivel egyszerűbb. Egy-két oldal esetén akár egy egyszerű kijelölés-másolás-beillesztés is megoldás lehet, valamivel nagyobb fájlok esetén PDF to Excel vagy az Adobe saját programja elegendő lehet – számos hasonló alkalmazás van, elég neten rákeresni.
Nagyobb volumenű munka esetén a Tabula lehet a nyerő – a program Windows és Linux alatt is fut, és ingyenes. A programozáshoz konyító felhasználók ugyanakkor scraping-gel is próbálkozhatnak – a scraperwiki pdf-tagje itt elérhető.
Sipos Zoltán
Támogasd a munkánkat bankkártyás fizetéssel az Átlátszónet Alapítványnak küldött rendszeres PayPal-adománnyal! Köszönjük.
Bankszámlaszám: 12011265-01425189-00100001
Bank neve: Raiffeisen Bank
Számlatulajdonos: Átlátszónet Alapítvány
1084 Budapest, Déri Miksa utca 10.
IBAN (EUR): HU36120112650142518900400002
IBAN (USD): HU36120112650142518900500009
SWIFT: UBRTHUHB
Számlatulajdonos: Átlátszónet Alapítvány
1084 Budapest, Déri Miksa utca 10.
Bank neve és címe: Raiffeisen Bank
(H-1133 Budapest, Váci út 116-118.)
Ha az 1 százalékodat az Átlátszó céljaira, projektjeire kívánod felajánlani, a személyi jövedelemadó bevallásodban az Átlátszónet Alapítvány adószámát tüntesd fel: 18516641-1-42
1% TÁMOGATÁS

Támogasd a munkánkat 10 ezer forint adománnyal, mi pedig megajándékozunk egy pólóval. Katt a részletekért.
Támogasd a munkánkat palackvisszaváltással, kattints az üvegvisszaváltós oldalra, mentsd el a kódunkat, és használd azt a Repontoknál!
Ha van bankkártyád, akkor pár kattintással gyorsan tudsz rendszeres vagy egyszeri támogatást beállítani nekünk az adjukossze.hu oldalán.


Postai befizetéssel is tudsz minket támogatni, amihez „sárga csekket” küldünk. Add meg a postacímedet, és már repül is a csekk.
Néző, Szurkoló, B-közép és VIP-páholy kategóriás Átlátszó-előfizetések között válogathatsz a Patreonon.
Bárhol is dolgozol a világban, ha a munkáltatód lehetőséget ad arra, hogy adott összeget felajánlj egy nonprofit szervezetnek, akkor ne feledd, a Benevity-n keresztül az Átlátszónet Alapítvány is ajánlható.
Ha az 1 százalékodat az Átlátszó céljaira, projektjeire kívánod felajánlani, a személyi jövedelemadó bevallásodban az Átlátszónet Alapítvány adószámát tüntesd fel: 18516641-1-42
A New Land Media Kft. és a Media Dynamics Kft. feladata lesz a turisztikai kereslet ösztönzése belföldön és külföldön egyaránt.

Az ősszel megjelent Újságírás-etika Kelet-Európában című könyv szerzőivel beszélgettünk.

A felcsúti milliárdos autós cége nem először nyer hasonló körülmények között. A társaság bevétele tavaly meghaladta a 18 milliárd forintot.

Katus Eszter Szerető Szabolccsal és Dévényi István újságíróval beszélte át a hét legfontosabb közéleti eseményeit a Magyar Hang műsorában.
Támogasd a munkánkat banki átutalással. Az adományokat az Átlátszónet Alapítvány számlájára utalhatod. Az utalás közleményébe írd: „Adomány”, köszönjük!